
Merhabalar, bu yazıda Deep Learning ile model eğitimi gibi birçok işlemin gerçekleştirilmesi için kullanılan Google Colab kullanımı hakkında bahsedeceğim ve pratik bilgiler vereceğim.
Kaggle üzerinde bulduğum Humpback Whale Identification veri seti ile supervised learning türünde model eğitimi yapacağız. Veri seti içerisindeki resimleri kullanarak model eğitimi gerçekleştireceğiz.
İlk başta File -> New notebook tıklayarak yeni bir notebook oluşturuyoruz. Oluşturduktan ve script’inizi yazmaya başladıktan sonra yine File menüsünden script’inizi drive’ınıza kaydedebilir veya kendi bilgisayarınızda Jupyter Notebook ile çalıştırmak üzere notebook türünde script’inizi indirebilirsiniz.
Veri Setinin İndirilmesi
Google Colab, Google Drive ile entegre olabilen bir yapıdır. Google Drive’ınıza verileri yükleyip Google Colab ile verilere erişerek işlemlerinizi gerçekleştirebilirsiniz. Sol tarafta Dosya simgesine tıkladığınızda size atanmış olan sanal makineye dosya upload edebilir veya sanal makinenizi Mount Drive seçeneği ile Google Drive entegresi gerçekleştirerek script içerisinde dosyalarınızı kullanabilirsiniz. Gerekli kütüphaneleri import edip Kaggle API entegresi gerçekleştirelim:
import json
import zipfile
import os
!mkdir ~/.kaggle
api_token = {"username":"nurettinabaci","key":"9fe6fbb14e374cc22ba300e4cbe2d004"}
with open('/root/.kaggle/kaggle.json', 'w') as file:
json.dump(api_token, file)
!echo '{"username":"nurettinabaci","key":"9fe6fbb14e374cc22ba300e4cbe2d004"}' > /root/.kaggle/kaggle.json
!kaggle config set -n path -v /content
!chmod 600 /root/.kaggle/kaggle.json
!cat /root/.kaggle/kaggle.jsonVeri setini Kaggle’dan indirmek için şu kodla drive entegresi yapacağım:
from google.colab import drive
drive.mount('/content/drive')Aşağıdaki kodla veri setini kendi drive’ıma yüklüyorum.
!kaggle competitions download -c humpback-whale-identification -p /content/drive/My\ Drive/kaggle/humpback-whale-identificationVeri seti direk jpeg olarak değil sıkıştırılmış dosya biçiminde inecektir. Biz unzip işlemi gerçekleştireceğiz. İlk olarak geçerli dizini dosyanın indirildiği dizine ayarlayalım.
os.chdir("/content/drive/My Drive/kaggle/humpback-whale-identification")Normalde !unzip komutuyla dosyaları çıkardığımızda output olarak çıkarılan dosyaların hepsinin ismini output kutusuna yazacaktır. Binlerce dosya çıkacağı için bu bilgisayarınızın RAM’ini yiyecektir ve en sonunda session çökecektir. Bu yüzden ilk önce output yazılmasını devre dışı bırakarak işlemi öyle gerçekleştiriyorum.
%%capture
!pip install adjustText
!unzip humpback-whale-identification.zip -d trainDosyaları kontrol amaçlı isimlerini ekrana yazdırabilirsiniz.
os.listdir("/content/drive/My Drive/kaggle/humpback-whale-identification")Train İşlemi
İşleme başlamadan önce birkaç ayar yapalım ki uzun süre çalışacak olan eğitim işleminin ortasında session veya bilgisayarımız patlamasın ve saatlerimiz boşa gitmesin.
Bir session atanması için sağ üstteki Connect butonuna tıklıyoruz. Colab size hemen bir sanal makine atayacaktır. Belli büyüklükte depolama alanı, RAM ve CPU bağlayacaktır. Bağlanan ram ve depolama boyutunu öğrenmek için imleci aynı yere tutabilirsiniz.

Resim 1’de görüldüğü gibi GPU kullanılmaktadır. Bunu Edit -> Notebook settings sekmesinden CPU/GPU/TPU seçimi yapabilirsiniz.
Google Colab üzerinde normal CPU, Tesla K80 GPU ile veya Google tarafından geliştirilen TPU ile eğitim işlemi gerçekleştirilebilmektedir. Model eğitimi sırasında konvolüsyon işlemi kullanılacağından CPU yerine GPU ile eğitimi seçeceğim. TPU ise Google tarafından geliştirilen, veriseti boyutu büyük olduğunda genellikle GPU’dan daha performanslı çalıştığı için tercih edilen bir birimdir. Kullandığım veri seti fazla büyük olmadığından GPU ile modelimi eğitmek mantıklıdır.
Ayrıca output kutucuğuna yazılacak mesaj uzunluğunu 100 karaktere sınırlıyorum, ram dolmasın.
import pandas as pd #Kullanacağım kütüphane
os.chdir("/content/drive/My Drive/kaggle/humpback-whale-identification") # Eğitime başlamadan önce dosya kontrolü yapıyorum
pd.set_option('display.max_colwidth',100) #100 karaktere sınırlaArtık başlayalım. İlk olarak kullanacağım kütüphaneleri import ediyorum.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.image as mplimg
from matplotlib.pyplot import imshow
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
import keras
from keras import layers
from keras.preprocessing import image
from keras.applications.imagenet_utils import preprocess_input
from keras.layers import Input, Dense, Activation, BatchNormalization, Flatten, Conv2D
from keras.layers import AveragePooling2D, MaxPooling2D, Dropout
from keras.models import Model
import keras.backend as K
from keras.models import Sequential
import warnings
warnings.simplefilter("ignore", category=DeprecationWarning)GPU kontrolü gerçekleştiriyorum.
import tensorflow as tf
tf.test.gpu_device_name()Daha sonra eğitim için kullanacağım veriyi kontrol amacıyla ilk 5 satırını yazdırıyorum:
train_df = pd.read_csv("train.csv")
train_df.head()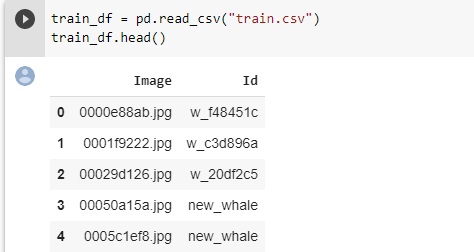
Sıra geldi resimleri eğitim için hazır hale getirmeye. Preprocessing ( ön işleme) fonksiyonlarını oluşturup resimlerin hepsini eğitim için uygun boyuta getirelim:
def prepareImages(data, m, dataset):
print("Preparing images")
X_train = np.zeros((m, 100, 100, 3))
count = 0
for fig in data['Image']:
#load images into images of size 100x100x3
img = image.load_img(dataset+"/"+fig, target_size=(100, 100, 3))
x = image.img_to_array(img)
x = preprocess_input(x)
X_train[count] = x
if (count%500 == 0):
print("Processing image: ", count+1, ", ", fig)
count += 1
return X_trainTanımladığımız fonksiyonla resimleri işliyoruz ve 255 ile bölerek normalize işlemi gerçekleştiriyoruz.
X = prepareImages(train_df, train_df.shape[0], "train")
X /= 255Sıra verilerin label’larını (etiket) encoder ile eğitim için hazır hale getirmeye geldi.
def prepare_labels(y):
values = np.array(y)
label_encoder = LabelEncoder()
integer_encoded = label_encoder.fit_transform(values)
onehot_encoder = OneHotEncoder(sparse=False)
integer_encoded = integer_encoded.reshape(len(integer_encoded), 1)
onehot_encoded = onehot_encoder.fit_transform(integer_encoded)
y = onehot_encoded
return y, label_encoderTanımladığımız fonksiyonla label’ları hazırlıyoruz.
y, label_encoder = prepare_labels(train_df['Id'])
y.shapeResimlerimiz eğitim için hazır hale geldi. Eğitim için kullanacağımız veri modelini oluşturalım:
model = Sequential()
model.add(Conv2D(32, (5, 5), strides = (1, 1), name = 'conv0', input_shape = (100, 100, 3)))
model.add(BatchNormalization(axis = 3, name = 'bn0'))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(MaxPooling2D((2, 2), (2,2), name='max_pool'))
model.add(Conv2D(64, (3, 3), strides = (1,1), name="conv1"))
model.add(Activation('relu'))
model.add(AveragePooling2D((2, 2), name='avg_pool'))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(500, activation="relu", name='rl'))
model.add(Dropout(0.4))
model.add(Dense(y.shape[1], activation='softmax', name='sm'))
from keras.optimizers import Adam
adam_optimizer = Adam(lr = 0.001, beta_1 = 0.9, beta_2 = 0.999)
model.compile(loss='categorical_crossentropy', optimizer=adam_optimizer, metrics=['accuracy'])
model.summary()Oluşturduğumuz modelin katmanları şu şekilde olacaktır:
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv0 (Conv2D) (None, 96, 96, 32) 2432
_________________________________________________________________
bn0 (BatchNormalization) (None, 96, 96, 32) 128
_________________________________________________________________
activation_5 (Activation) (None, 96, 96, 32) 0
_________________________________________________________________
dropout_3 (Dropout) (None, 96, 96, 32) 0
_________________________________________________________________
max_pool (MaxPooling2D) (None, 48, 48, 32) 0
_________________________________________________________________
conv1 (Conv2D) (None, 46, 46, 64) 18496
_________________________________________________________________
activation_6 (Activation) (None, 46, 46, 64) 0
_________________________________________________________________
avg_pool (AveragePooling2D) (None, 23, 23, 64) 0
_________________________________________________________________
dropout_4 (Dropout) (None, 23, 23, 64) 0
_________________________________________________________________
flatten_3 (Flatten) (None, 33856) 0
_________________________________________________________________
rl (Dense) (None, 500) 16928500
_________________________________________________________________
dropout_5 (Dropout) (None, 500) 0
_________________________________________________________________
sm (Dense) (None, 5005) 2507505
=================================================================
Total params: 19,457,061
Trainable params: 19,456,997
Non-trainable params: 64
_________________________________________________________________Herşey hazır halde. Artık model eğitimine geçebiliriz. Tüm resimler 100 defa kullanılarak ve eğitim sırasında 1000 resim büyüklüğünde batch ile model eğitilecektir. Çalışma sırasında eğitimin hangi aşamada olduğu ekrana yazdırılacaktır:
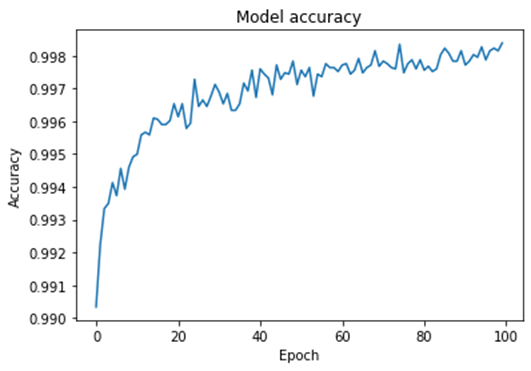
history = model.fit(X, y, epochs=100, batch_size=1000, verbose=1)Model eğitildikten sonra çıktının bir kısmı:
Epoch 1/100
25361/25361 [==============================] - 12s 463us/step - loss: 0.0369 - acc: 0.9903
Epoch 2/100
25361/25361 [==============================] - 11s 425us/step - loss: 0.0294 - acc: 0.9922
Epoch 3/100
25361/25361 [==============================] - 11s 424us/step - loss: 0.0263 - acc: 0.9933
Epoch 4/100
25361/25361 [==============================] - 11s 422us/step - loss: 0.0249 - acc: 0.9935
Epoch 5/100
25361/25361 [==============================] - 11s 421us/step - loss: 0.0250 - acc: 0.9941
.....Model accuracy’sini bastıralım:
Test Aşaması
Modelimizi test edip ne kadar güvenilir olduğuna bakalım.
test = os.listdir("/content/drive/My Drive/kaggle/humpback-whale-identification/test")
print(len(test))Çıktı sonucu 7960 olarak yazdırılmıştır.
Test için kullanacağım resimleri de işliyorum:
Z = prepareImages(test_df, test_df.shape[0], "test")
Z /= 255Preparing images
Processing image: 1 , df0ba6ec9.jpg
Processing image: 501 , f2c2ced53.jpg
Processing image: 1001 , c03dedb0d.jpg
Processing image: 1501 , cdb79cead.jpg
....Resimler işlendikten sonra test kodunu çalıştırıyorum:
predictions = model.predict(np.array(Z), verbose=1)7960/7960 [==============================] - 2s 211us/stepfor i, pred in enumerate(predictions):
test_df.loc[i, 'Id'] = ' '.join(label_encoder.inverse_transform(pred.argsort()[-5:][::-1]))
test_df.head(10)
test_df.to_csv('submission.csv', index=False)Google Colab kullanımı üzerinde örnek model eğitimi gerçekleştirdik.
Aşağıda geçenlerde internet üzerinde bu uygulamaya denk geldim.1985 senesindeki bir balina ile, kuyruk fotoğrafı yardımıyla 2020 senesinde tekrar karşılaşılmış:

Bir sonraki yazıda görüşmek üzere.