
When it comes to understanding how a file system works in Linux, it’s essential to delve into its implementation details. In this blog post, we will explore the key aspects of file system implementation, including the necessary data structures, their organization on disk, and the access methods employed to handle file operations efficiently.
It’s important to note that a file system is purely software-based. Unlike the hardware features we add to enhance the performance of CPUs and memory virtualization, the file system relies on software implementations to effectively manage files and directories.
So, how does one go about implementing a simple file system? What are the necessary data structures that need to be present on the disk? How can we access and manipulate these structures?
To gain a comprehensive understanding of file systems, it’s crucial to consider two key aspects: data structures and access methods. By grasping these concepts, you’ll have a solid foundation for comprehending the inner workings of the file system.
Data Structures in File Systems
The first aspect to delve into is the data structures utilized by the file system to organize its data and metadata. In simpler file systems, basic structures like arrays of blocks or objects are employed. However, more advanced file systems, such as SGI’s XFS, adopt complex tree-based structures to achieve higher efficiency and flexibility.
For instance, traditional file systems like ext4 and FAT32 make use of a hierarchical structure consisting of directories and files. Directories serve as containers that hold references to files or subdirectories, creating a hierarchical organization of data. On the other hand, more modern file systems like ZFS employ advanced techniques such as pooling, copy-on-write snapshots, and data checksumming to ensure data integrity and enhance performance.
Access Methods in File Systems
The second aspect revolves around how the file system maps the system calls made by processes onto its underlying data structures. System calls like open(), read(), write(), and others are the means through which processes interact with files and directories.
During the execution of a system call, the file system determines which structures need to be read and which ones need to be modified. It strives to optimize these operations to achieve efficient file access and manipulation.
For example, when a process invokes the open() system call to access a file, the file system will locate the appropriate directory entry and retrieve the corresponding inode, which contains the metadata of the file. Similarly, when a read() system call is made, the file system retrieves the required data blocks associated with the file.
Moreover, file systems employ caching mechanisms to reduce disk I/O operations and improve performance. By caching frequently accessed data and metadata in memory, subsequent accesses can be served faster, minimizing the need for disk access.
Building the On-Disk Structure of the Linux File System
In order to implement a functional file system, it’s crucial to establish the overall on-disk organization of the data structures. Let’s take a deep dive into the key components involved and understand how they work together to form the Linux file system.
Dividing the Disk into Blocks
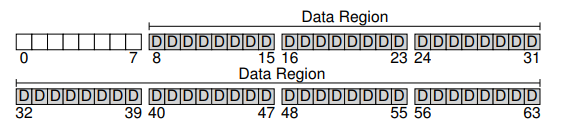
The first step in the process is dividing the disk into blocks. In the case of a simple file system, a single block size is used. For our example, we’ll utilize a commonly-used block size of 4 KB. In a nutshell, the disk partition consists of a series of blocks, each with a size of 4 KB. These blocks are addressed from 0 to N - 1, where N represents the total number of blocks in the partition.

Data Region and User Data
One essential aspect of any file system is user data. The majority of the space in a file system is dedicated to storing user data. We refer to the region of the disk used for user data as the data region. To keep things simple, let’s allocate the last 56 blocks out of the total 64 blocks on the disk for user data storage.
Inodes: Tracking File Information
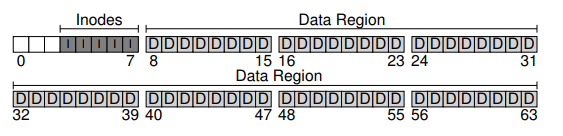
File systems need to track various information about each file. This metadata includes details such as the composition of data blocks belonging to a file, file size, ownership, access rights, and timestamps. To store this information, file systems utilize a structure called an inode. An inode acts as a key piece of metadata and holds critical information about a file.
To accommodate inodes, a portion of the disk needs to be reserved. This area is known as the inode table and it holds an array of on-disk inodes. Typically, inodes are relatively small in size, ranging from 128 to 256 bytes. For instance, assuming 256 bytes per inode, a 4-KB block can hold 16 inodes. In our simple file system example, we have a total of 80 inodes.
Allocation Structures: Tracking Free and Allocated Blocks
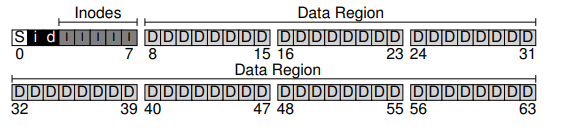
A vital component that must be present in any file system is a mechanism to track whether inodes or data blocks are free or allocated. There are various allocation-tracking methods available, but we will focus on a widely-used structure known as a bitmap.
In our case, we require two bitmaps: the data bitmap to track the allocation status of data blocks in the data region, and the inode bitmap to track the allocation status of inodes in the inode table. Although using an entire 4-KB block for these bitmaps may seem excessive, it simplifies the implementation.

Superblock: File System Information
A remaining block in the on-disk structure design is reserved for the superblock. The superblock contains crucial information about the file system itself. This includes the number of inodes and data blocks present in the file system (80 inodes and 56 data blocks in our example), the starting point of the inode table (block 3), and other relevant details. The superblock often includes a magic number, serving as an identifier for the file system type.
During the mounting process of a file system, the operating system reads the superblock first to initialize various parameters. It then attaches the volume to the file system tree. When files within the volume are accessed, the system knows precisely where to locate the required on-disk structures based on the information provided by the superblock.
File Organization: Exploring the Inode Structure in Linux File Systems
In the realm of file systems, the inode is a crucial on-disk structure found in virtually all file systems. The term “inode” is derived from “index node,” the original name given to it in UNIX. Each inode is associated with a unique identifier known as the i-number, which serves as the low-level name of the file.
In simple file systems, given an i-number, it’s possible to calculate the exact location of the corresponding inode on the disk. Let’s consider the inode table of a simple file system, which spans 20KB in size (equivalent to five 4KB blocks) and contains a total of 80 inodes (assuming each inode occupies 256 bytes). Assuming that the inode region starts at 12KB (following the superblock at 0KB, inode bitmap at 4KB, and data bitmap at 8KB), we can determine the byte address of the desired block of inodes.
For instance, to read inode number 32, the file system would calculate the offset into the inode region by multiplying the inode number by the size of each inode (32 * sizeof(inode) or 8192). This offset is then added to the start address of the inode table on disk (inodeStartAddr = 12KB), resulting in the correct byte address of the desired block of inodes: 20KB. It’s important to note that disks are not byte addressable but are comprised of addressable sectors, typically 512 bytes in size. Therefore, to retrieve the block of inodes containing inode 32, the file system would issue a read operation to sector 20 * 1024 / 512, or 40, to fetch the desired inode block. More generally, the sector address of the inode block can be calculated using the following formula:
blk = (inumber * sizeof(inode_t)) / blockSize;
sector = ((blk * blockSize) + inodeStartAddr) / sectorSize;Within each inode lies a wealth of information about a file. This includes the file’s type (e.g., regular file, directory, etc.), its size, the number of blocks allocated to it, protection information (such as ownership), and more. All such information related to a file is referred to as metadata within the file system. Essentially, any data present in the file system that isn’t considered user data falls into this metadata category.
One critical design consideration for inodes is determining how they reference data blocks. A straightforward approach involves having one or more direct pointers (disk addresses) stored inside the inode, where each pointer corresponds to a disk block allocated to the file. However, this approach has limitations. For instance, if there is a need for a file that surpasses the size of the block multiplied by the number of direct pointers in the inode, this design falls short.
Efficient File Storage: The Power of Multi-Level Indexing and Extents in Linux File Systems
As file systems evolve to handle larger files, innovative structures have been introduced within inodes to optimize storage efficiency. One common concept is the use of an indirect pointer, which provides a means to reference blocks containing additional pointers to user data, rather than directly pointing to data blocks. By incorporating these indirect pointers, file systems can support files of greater size by extending the reach of a single inode.
In this approach, an inode typically includes a fixed number of direct pointers (e.g., 12) alongside a single indirect pointer. However, the need for even larger files has led to the introduction of the double indirect pointer. This additional pointer points to a block that houses pointers to indirect blocks, each of which, in turn, holds pointers to data blocks. By employing a double indirect block, the file system can support file sizes that exceed 4GB, accommodating an additional 1 million 4KB blocks. And, as you might have guessed, there’s one more level of indirection: the triple indirect pointer.
This tree-like structure, known as the multi-level index approach, enables efficient referencing of file blocks. Let’s consider an example with twelve direct pointers, a single indirect block, and a double indirect block. Assuming a block size of 4KB and 4-byte pointers, this arrangement can handle files just over 4GB in size (i.e., (12 + 1024 + 1024^2) × 4KB). If you’re up for a challenge, can you determine the file size limit achievable by adding a triple indirect block? (hint: it’s quite substantial)
While the multi-level index approach serves many file systems well, others have adopted a different strategy. Systems like SGI XFS and Linux ext4 employ a concept called extents instead of simple pointers. An extent is essentially a disk pointer combined with a length value, representing a contiguous block range on the disk where a file resides. Rather than requiring a pointer for every file block, extents offer a more compact representation by specifying the location of a file using just a pointer and length. However, a single extent can pose limitations, particularly when allocating a file and finding contiguous free space on the disk. To address this, extent-based file systems often allow for multiple extents, granting greater flexibility during file allocation.
By incorporating multi-level indexing and extents, modern Linux file systems optimize storage allocation and enable efficient management of large files. These advancements play a crucial role in providing a scalable and robust infrastructure for file storage, empowering users to handle data-intensive workloads effectively.
Organizing Directories: A Closer Look at Directory Management in Linux File Systems
When it comes to file systems, managing directories involves more than just creating and accessing files. The deletion of a file, for instance, introduces the need for a mechanism to handle empty spaces within directories. To address this, a solution like marking the space with a reserved inode number, such as zero, can be employed. By doing so, the file system can effectively manage and utilize the available space within directories, even after deletions occur.
Now, let’s take a moment to understand where directories themselves are stored within a file system. In many file systems, directories are treated as a distinct type of file. Consequently, each directory is associated with an inode, which resides somewhere in the inode table. However, unlike regular files, the type field of the directory’s inode is marked as “directory.” The inode points to data blocks that store the actual content of the directory, and in some cases, indirect blocks may be utilized as well. These data blocks reside in the data block region of the file system, while the overall on-disk structure of the file system remains unchanged.
By treating directories as special files with their own inodes, Linux file systems enable efficient management of directory structures. This approach ensures that directories can be easily accessed, modified, and updated as needed. Moreover, the use of inodes allows for the implementation of various directory-related operations, such as listing the contents of a directory, creating new files within a directory, and navigating the file system hierarchy.
Efficiently Managing Free Space in Linux File Systems
Free space management is a critical aspect of file system design, ensuring that available space can be effectively allocated for new files and directories. While there are multiple approaches to managing free space, one commonly used technique is the utilization of bitmaps. However, it’s worth noting that various file systems may employ different strategies to handle this task efficiently.
In early file systems, a popular method of free space management was the use of free lists. This involved maintaining a single pointer in the superblock that pointed to the first free block. Inside that block, a pointer to the next free block was stored, forming a linked list of free blocks throughout the system. When a block was required, the head block of the free list was utilized, and the list was updated accordingly.
Regardless of the specific technique employed, a file system needs to keep track of which inodes and data blocks are free and which are in use. This information allows the file system to identify and allocate suitable space for new files and directories.
When creating a new file, the file system searches the bitmap for a free inode and allocates it to the file. The corresponding inode in the bitmap is marked as used (represented by a 1), and the on-disk bitmap is updated accordingly. Similarly, when allocating data blocks for a file, a similar process occurs. The file system scans the bitmap for a sequence of free blocks and assigns them to the file. This approach not only ensures that space is available but also allows for the creation of contiguous portions of the file on disk, thereby enhancing performance.
It’s worth mentioning that some Linux file systems, like ext2 and ext3, employ additional strategies during data block allocation. These file systems seek out a sequence of free blocks (e.g., 8 blocks) when creating a new file. By allocating such a contiguous sequence of free blocks to the file, these file systems ensure that a portion of the file remains physically adjacent on the disk. This pre-allocation policy serves as a widely used heuristic to optimize data block allocation and improve overall system performance.
Exploring the Access Path: Reading and Writing in Linux File Systems
In our journey to understand how a file system works, it is essential to examine the flow of operations involved in reading or writing a file. By gaining insights into this access path, we can develop a deeper understanding of the file system’s inner workings. So, let’s dive into the details and explore what happens during these file access activities.
Let’s assume that the file system has already been mounted, meaning that the superblock is loaded into memory. However, all other components, such as inodes and directories, remain on the disk.
Let’s start with a simple scenario where you want to open a file, read its contents, and then close it. We’ll use the file path “/foo/bar” as an example, and assume that the file is 12KB in size (occupying 3 blocks).
When you call the open("/foo/bar", O_RDONLY) function, the file system needs to locate the inode corresponding to the file “bar.” The inode provides essential information about the file, such as permissions and file size. However, the file system currently only has the full pathname. To find the inode, it traverses the pathname, searching for the desired file.
All traversals begin at the root of the file system, denoted by the root directory (“/”). Therefore, the file system first reads the inode of the root directory from the disk.
Once the inode of the root directory is loaded into memory, the file system can examine its pointers to data blocks, which store the contents of the root directory. By following these on-disk pointers, the file system reads through the directory and locates an entry for “foo.” By reading one or more directory data blocks, it discovers the entry for “foo” and obtains the inode number associated with it (let’s say it’s 44), which is the next piece of information required.
The next step involves recursively traversing the pathname until the desired inode for “bar” is found. In our example, the file system reads the block containing the inode for “foo” and then its directory data, eventually locating the inode number for “bar.” As part of the open() process, the file system reads the inode of “bar” into memory, performs a final permissions check, allocates a file descriptor in the per-process open-file table, and returns it to the user.
Once the file is open, the program can initiate a read() system call to read from the file. The first read, starting at offset 0 (unless lseek() has been used), fetches the first block of the file. The file system consults the inode to determine the block’s location and may also update the inode with a new last accessed time. The read() operation further updates the in-memory open file table associated with the file descriptor, adjusting the file offset to indicate the position for the subsequent read operation, such as reading the second file block, and so on.
At some point, the file is closed. The closing process involves deallocating the file descriptor, which is the primary task for the file system in this case. No disk I/O operations are necessary at this stage.
It’s worth noting that the amount of I/O generated during the open() operation is proportional to the length of the pathname. With each additional directory in the path, the file system needs to read its inode as well as its data.
File Writing in Linux File Systems
In our deep dive into how Linux file and directory systems work, we have already covered the process of reading files. Now, let’s shift our focus to writing files and explore the intricate steps involved in storing data on disk. Unlike reading, the act of writing a file may require allocating a new block unless the data is being overwritten. This means that each write operation not only involves writing data to disk but also requires making decisions about block allocation and updating various disk structures, such as the data bitmap and inode. As a result, every write to a file logically generates five I/O operations.
To understand this better, let’s examine the steps performed during a write operation to a new file. When writing a new file, each write action encompasses five I/O operations. Firstly, the data bitmap is read to determine the availability of blocks. If a block is allocated, the data bitmap is updated to mark the newly allocated block as used. Then, the bitmap is written back to disk to reflect the updated state. Next, two additional I/O operations are performed to read and write the inode, which is updated with the location of the new block. Finally, the actual data block is written to disk, resulting in the fifth I/O operation.
The amount of write traffic becomes even more significant when we consider a common operation like file creation. When creating a file, the file system must allocate an inode and allocate space within the directory that will contain the new file. The overall I/O traffic involved in this process is substantial. It includes one read operation to the inode bitmap to find a free inode, one write operation to the inode bitmap to mark the inode as allocated, one write operation to initialize the new inode, one read operation to access the data of the directory and link the high-level name of the file to its inode number, and one read and one write operation to update the directory inode. If the directory needs to expand to accommodate the new entry, additional I/O operations to the data bitmap and the new directory block are also required. All of this complexity is involved in creating just one file.
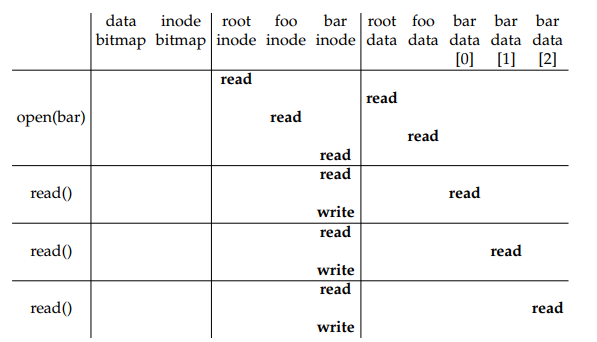
To illustrate the intricacies of file creation and writing, let’s examine a specific example. Consider the scenario where the file "/foo/bar" is created, and three 4KB blocks are written to it.
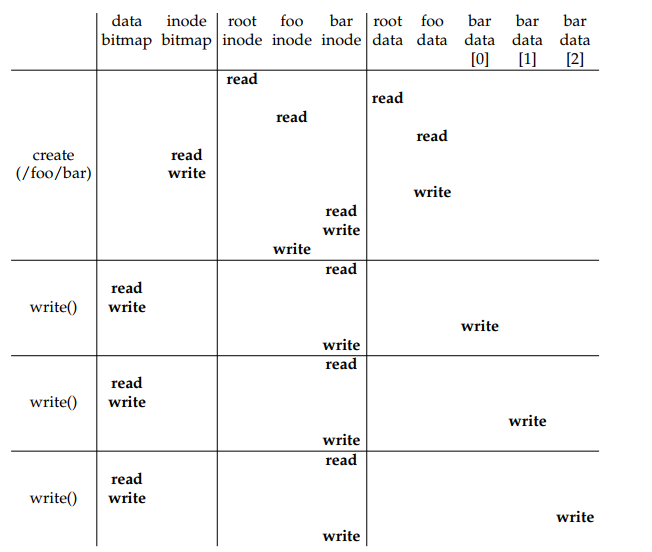
In the figure, the disk reads and writes are grouped based on the system call that triggered them, and their rough ordering is depicted from top to bottom. By examining the figure, we can observe the substantial effort required to create a file. In this example, it involves a total of ten I/O operations, including traversing the pathname and finally creating the file. Furthermore, each allocating write incurs five I/O operations: a pair to read and update the inode, another pair to read and update the data bitmap, and finally, the write operation for the actual data.
Caching and Buffering in File Systems: Optimizing Performance
In our exploration of how Linux file and directory systems work, we have delved into various aspects of file operations. Now, let’s shift our focus to caching and buffering, two essential mechanisms that play a crucial role in optimizing performance.
While caching helps improve read operations by keeping frequently accessed data in memory, write operations necessitate going to disk to ensure persistence. Therefore, a cache does not function as the same kind of filter for write traffic as it does for reads. Nonetheless, write buffering, also known as write caching, offers several performance benefits.
Firstly, by delaying writes, the file system can batch multiple updates into a smaller set of I/O operations. For example, if the inode bitmap is updated when one file is created and then updated again shortly after as another file is created, the file system saves an I/O operation by postponing the write after the first update. This batching of writes reduces the overall number of I/O operations and improves efficiency.
Secondly, by buffering a number of writes in memory, the system can optimize the scheduling of subsequent I/O operations, leading to increased performance. By intelligently managing the ordering and timing of writes, the file system can minimize latency and maximize throughput.
Additionally, some writes can be avoided altogether through delayed buffering. For instance, if an application creates a file and subsequently deletes it, delaying the writes to reflect the file creation on disk can entirely avoid unnecessary write operations. This approach of deferring writes when possible demonstrates the virtue of laziness in writing blocks to disk.
Considering these advantages, most modern file systems employ write buffering in memory for a specific duration, typically ranging from five to thirty seconds. However, this introduces a trade-off: if the system crashes before the updates have been propagated to disk, the updates may be lost. Nevertheless, the benefits of improved performance through batching, scheduling, and avoiding writes outweigh the potential risk in many scenarios.
It is important to note that certain applications, such as databases, prioritize data consistency over performance optimizations offered by write buffering. To mitigate the risk of unexpected data loss due to buffering, these applications employ different strategies. They may forcefully write data to disk by calling fsync(), utilize direct I/O interfaces that bypass the cache, or leverage the raw disk interface to bypass the file system entirely. By ensuring immediate and durable data writes, these applications guarantee data integrity at the cost of potential performance overhead.
Caching and buffering mechanisms are integral to the efficient functioning of file systems, providing a delicate balance between performance optimization and data durability. Understanding the trade-offs involved enables system designers and application developers to make informed decisions based on their specific requirements.
Resources
Operating Systems: Three Easy Pieces – Files System Implementation
